Model Prebuilts¶
MLC-LLM is a universal solution for deploying different language models. Any language models that can be described in TVM Relax (a general representation for Neural Networks and can be imported from models written in PyTorch) can be recognized by MLC-LLM and thus deployed to different backends with the help of TVM Unity.
The community has already supported several LLM architectures (LLaMA, GPT-NeoX, etc.) and have prebuilt some models (Vicuna, RedPajama, etc.) which you can use off the shelf. With the goal of democratizing the deployment of LLMs, we eagerly anticipate further contributions from the community to expand the range of supported model architectures.
This page contains the list of prebuilt models for our CLI (command line interface) app, iOS and Android apps. The models have undergone extensive testing on various devices, and their performance has been optimized by developers with the help of TVM.
Prebuilt Models for CLI¶
Model code |
Model Series |
Quantization Mode |
Hugging Face repo |
|---|---|---|---|
Llama-2-7b-q4f16_1 |
|
||
vicuna-v1-7b-q3f16_0 |
|
||
RedPajama-INCITE-Chat-3B-v1-q4f16_1 |
|
||
rwkv-raven-1b5-q8f16_0 |
|
||
rwkv-raven-3b-q8f16_0 |
|
||
rwkv-raven-7b-q8f16_0 |
|
To download and run one model with CLI, follow the instructions below:
# Create conda environment and install CLI if you have not installed.
conda create -n mlc-chat-venv -c mlc-ai -c conda-forge mlc-chat-cli-nightly
conda activate mlc-chat-venv
conda install git git-lfs
git lfs install
# Download prebuilt model binary libraries from GitHub if you have not downloaded.
mkdir -p dist/prebuilt
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git dist/prebuilt/lib
# Download prebuilt model weights and run CLI.
cd dist/prebuilt
git clone https://huggingface.co/mlc-ai/mlc-chat-[model-code]
cd ../..
mlc_chat_cli --local-id [model-code]
# e.g.,
# cd dist/prebuilt
# git clone https://huggingface.co/mlc-ai/mlc-chat-rwkv-raven-7b-q8f16_0
# cd ../..
# mlc_chat_cli --local-id rwkv-raven-7b-q8f16_0
Prebuilt Models for iOS¶
Model code |
Model Series |
Quantization Mode |
Hugging Face repo |
|---|---|---|---|
Llama-2-7b-q3f16_1 |
|
||
vicuna-v1-7b-q3f16_0 |
|
||
RedPajama-INCITE-Chat-3B-v1-q4f16_1 |
|
The downloadable iOS app has builtin RedPajama-3B model support. To add a model to the iOS app, follow the steps below:
Click to show instructions
Open “MLCChat” app, click “Add model variant”.
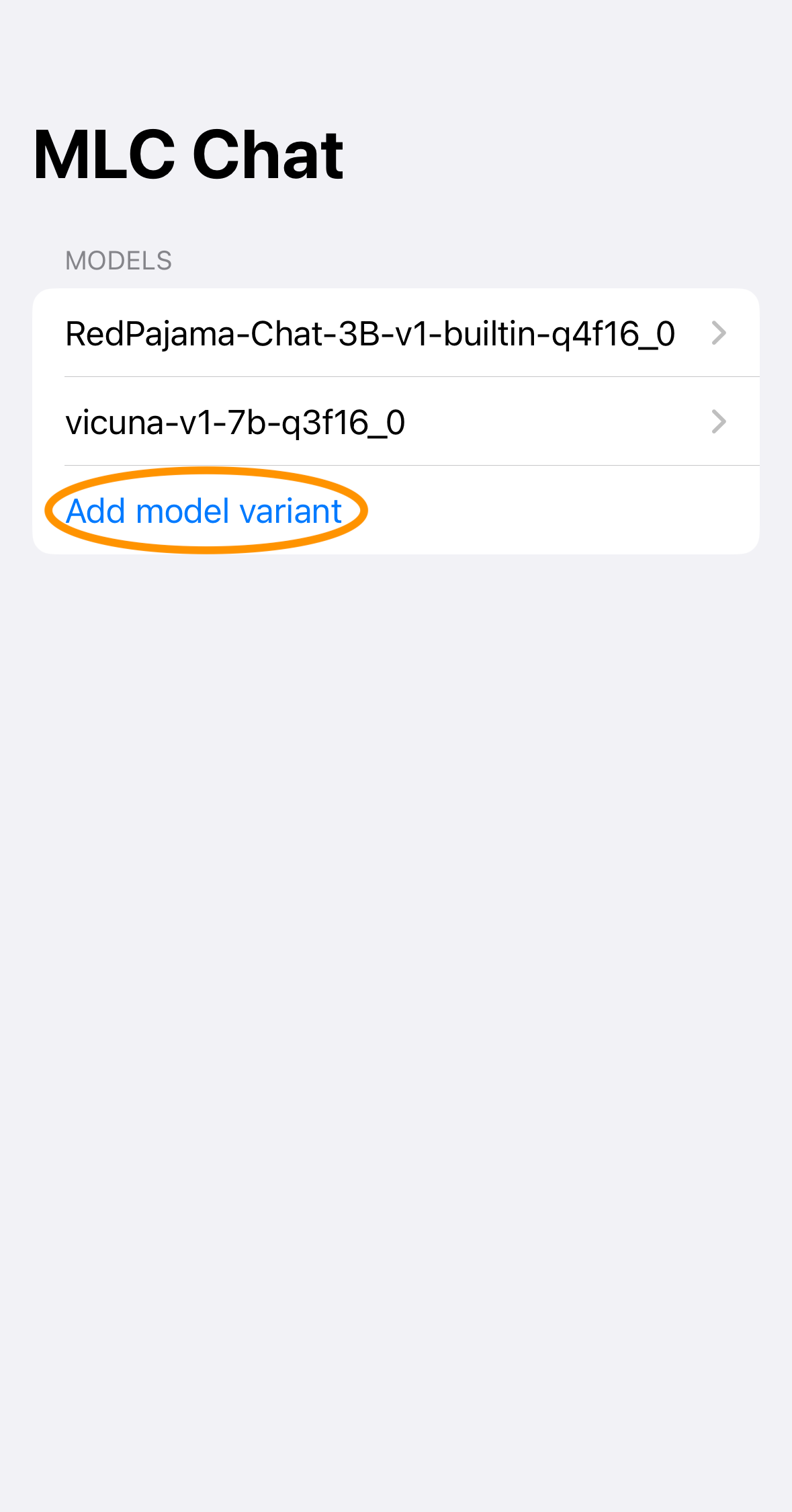
Paste the repository URL of the model built on your own, and click “Add”.
You can refer to the link in the image as an example.

After adding the model, you can download your model from the URL by clicking the download button.
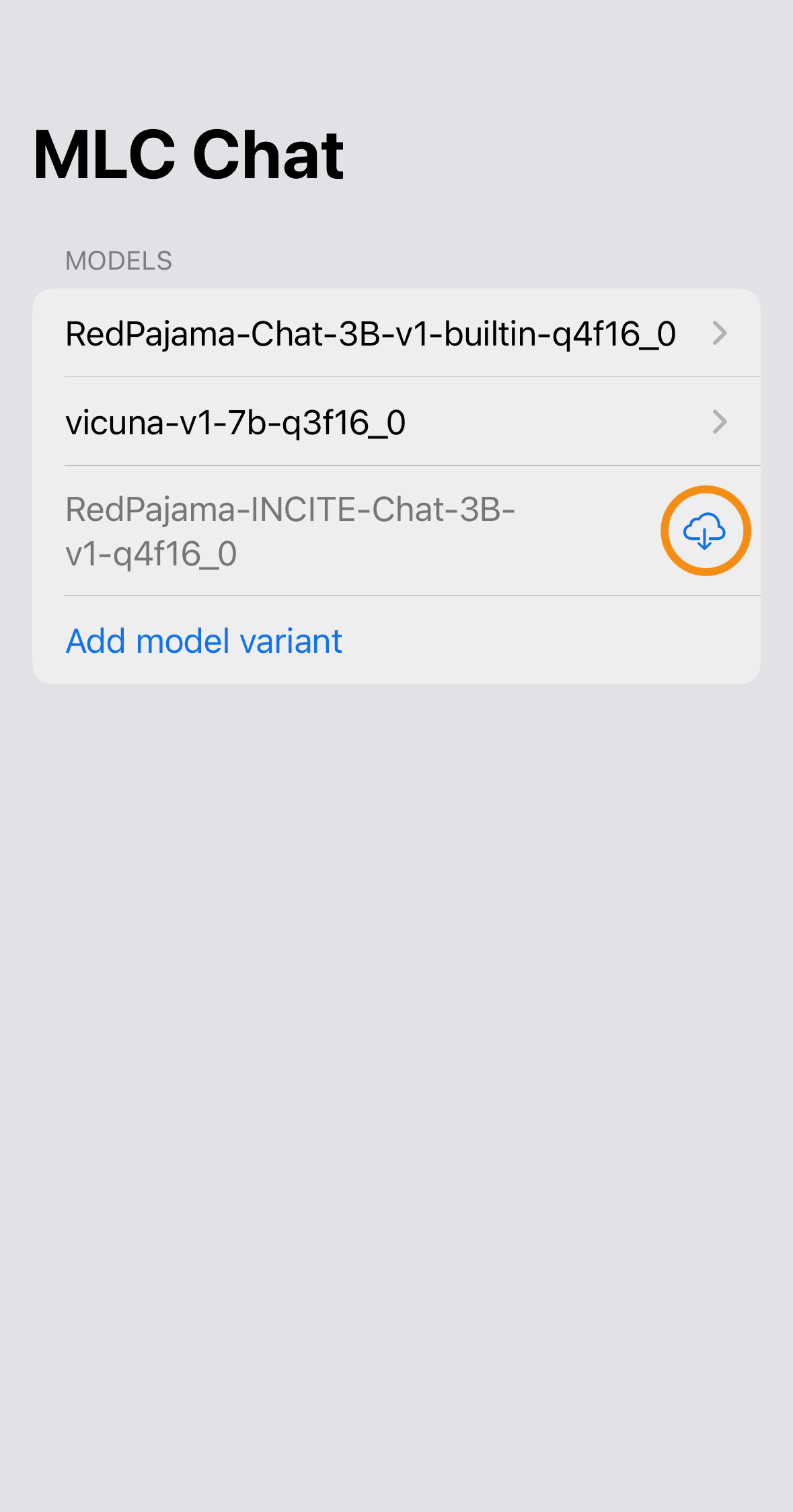
When the download is finished, click into the model and enjoy.
The iOS app has integrated with the following model libraries, which can be directly reused when you want to run a model you compiled in iOS, as long as the model is in the supported model family and is compiled with supported quantization mode.
For example, if you compile OpenLLaMA-7B with quantization mode q3f16_0, then you can run the compiled OpenLLaMA model on iPhone without rebuilding the iOS app by reusing the vicuna-v1-7b-q3f16_0 model library. Please check the model distribution page for detailed instructions.
Model library name |
Model Family |
Quantization Mode |
|---|---|---|
vicuna-v1-7b-q3f16_0 |
LLaMA |
|
RedPajama-INCITE-Chat-3B-v1-q4f16_1 |
GPT-NeoX |
|
Prebuilt Models for Android¶
Model code |
Model Series |
Quantization Mode |
Hugging Face repo |
|---|---|---|---|
vicuna-v1-7b-q4f16_1 |
|
||
RedPajama-INCITE-Chat-3B-v1-q4f16_0 |
|
You can check MLC-LLM pull requests to track the ongoing efforts of new models. We encourage users to upload their compiled models to Hugging Face and share with the community.
Supported Model Architectures¶
MLC-LLM supports the following model architectures:
Category Code |
Series |
Model Definition |
Variants |
|---|---|---|---|
|
|||
|
|||
|
|||
|
|||
|
|||
|
For models structured in these model architectures, you can check the model compilation page on how to compile models. Please create a new issue if you want to request a new model architecture. Our tutorial Define New Models introduces how to bring a new model architecture to MLC-LLM.
Contribute Models to MLC-LLM¶
Ready to contribute your compiled models/new model architectures? Awesome! Please check Contribute New Models to MLC-LLM on how to contribute new models to MLC-LLM.