Python API and Gradio Frontend¶
We expose Python API for the MLC-Chat for easy integration into other Python projects. We also provide a web demo based on gradio as an example of using Python API to interact with MLC-Chat.
Python API¶
The Python API is a part of the MLC-Chat package, which we have prepared pre-built pip wheels and you can install it by following the instructions in https://mlc.ai/package/.
Verify Installation¶
python -c "from mlc_chat import ChatModule; print(ChatModule)"
You are expected to see the information about the mlc_chat.ChatModule class.
If the prebuilt is unavailable on your platform, or you would like to build a runtime that supports other GPU runtime than the prebuilt version. Please refer our Build MLC-Chat Package From Source tutorial.
Get Started¶
After confirming that the package mlc_chat is installed, we can follow the steps
below to chat with a MLC-compiled model in Python.
First, let us make sure that the MLC-compiled model we want to chat with already exists.
Note
model has the format f"{model_name}-{quantize_mode}". For instance, if
you used q4f16_1 as the quantize_mode to compile Llama-2-7b-chat-hf, you
would have model being Llama-2-7b-chat-hf-q4f16_1.
If you do not have the MLC-compiled model ready:
Checkout Try out MLC Chat to download prebuilt models for simplicity, or
Checkout Compile Models via MLC to compile models with
mlc_llm(another package) yourself
If you downloaded prebuilt models from MLC LLM, by default:
Model lib should be placed at
./dist/prebuilt/lib/$(model)-$(arch).$(suffix).Model weights and chat config are located under
./dist/prebuilt/mlc-chat-$(model)/.
Example
>>> ls -l ./dist/prebuilt/lib
Llama-2-7b-chat-hf-q4f16_1-metal.so # Format: $(model)-$(arch).$(suffix)
Llama-2-7b-chat-hf-q4f16_1-vulkan.so
...
>>> ls -l ./dist/prebuilt/mlc-chat-Llama-2-7b-chat-hf-q4f16_1 # Format: ./dist/prebuilt/mlc-chat-$(model)/
# chat config:
mlc-chat-config.json
# model weights:
ndarray-cache.json
params_shard_*.bin
...
If you have compiled models using MLC LLM, by default:
Model libraries should be placed at
./dist/$(model)/$(model)-$(arch).$(suffix).Model weights and chat config are located under
./dist/$(model)/params/.
Example
>>> ls -l ./dist/Llama-2-7b-chat-hf-q4f16_1/ # Format: ./dist/$(model)/
Llama-2-7b-chat-hf-q4f16_1-metal.so # Format: $(model)-$(arch).$(suffix)
...
>>> ls -l ./dist/Llama-2-7b-chat-hf-q4f16_1/params # Format: ``./dist/$(model)/params/``
# chat config:
mlc-chat-config.json
# model weights:
ndarray-cache.json
params_shard_*.bin
...
After making sure that the files exist, using the conda environment you used
to install mlc_chat, from the mlc-llm directory, you can create a Python
file sample_mlc_chat.py and paste the following lines:
from mlc_chat import ChatModule
from mlc_chat.callback import StreamToStdout
# From the mlc-llm directory, run
# $ python sample_mlc_chat.py
# Create a ChatModule instance
cm = ChatModule(model="Llama-2-7b-chat-hf-q4f16_1")
# You can change to other models that you downloaded, for example,
# cm = ChatModule(model="Llama-2-13b-chat-hf-q4f16_1") # Llama2 13b model
output = cm.generate(
prompt="What is the meaning of life?",
progress_callback=StreamToStdout(callback_interval=2),
)
# Print prefill and decode performance statistics
print(f"Statistics: {cm.stats()}\n")
output = cm.generate(
prompt="How many points did you list out?",
progress_callback=StreamToStdout(callback_interval=2),
)
# Reset the chat module by
# cm.reset_chat()
Now run the Python file to start the chat
python sample_mlc_chat.py
You can also checkout the Model Prebuilts page to run other models.
See output
Using model folder: ./dist/prebuilt/mlc-chat-Llama-2-7b-chat-hf-q4f16_1
Using mlc chat config: ./dist/prebuilt/mlc-chat-Llama-2-7b-chat-hf-q4f16_1/mlc-chat-config.json
Using library model: ./dist/prebuilt/lib/Llama-2-7b-chat-hf-q4f16_1-cuda.so
Thank you for your question! The meaning of life is a complex and subjective topic that has been debated by philosophers, theologians, scientists, and many others for centuries. There is no one definitive answer to this question, as it can vary depending on a person's beliefs, values, experiences, and perspectives.
However, here are some possible ways to approach the question:
1. Religious or spiritual beliefs: Many people believe that the meaning of life is to fulfill a divine or spiritual purpose, whether that be to follow a set of moral guidelines, to achieve spiritual enlightenment, or to fulfill a particular destiny.
2. Personal growth and development: Some people believe that the meaning of life is to learn, grow, and evolve as individuals, to develop one's talents and abilities, and to become the best version of oneself.
3. Relationships and connections: Others believe that the meaning of life is to form meaningful connections and relationships with others, to love and be loved, and to build a supportive and fulfilling social network.
4. Contribution and impact: Some people believe that the meaning of life is to make a positive impact on the world, to contribute to society in a meaningful way, and to leave a lasting legacy.
5. Simple pleasures and enjoyment: Finally, some people believe that the meaning of life is to simply enjoy the present moment, to find pleasure and happiness in the simple things in life, and to appreciate the beauty and wonder of the world around us.
Ultimately, the meaning of life is a deeply personal and subjective question, and each person must find their own answer based on their own beliefs, values, and experiences.
Statistics: prefill: 3477.5 tok/s, decode: 153.6 tok/s
I listed out 5 possible ways to approach the question of the meaning of life.
Note
You could also specify the address of model and lib_path explicitly. If
you only specify model as model_name and quantize_mode, we will
do a search for you. See more in the documentation of mlc_chat.ChatModule.__init__().
Tutorial with Python Notebooks¶
Now that you have tried out how to chat with the model in Python, we would recommend you to checkout the following tutorials in Python notebook (all runnable in Colab):
Getting Started with MLC-LLM: how to quickly download prebuilt models and chat with it
Compiling Llama-2 with MLC-LLM: how to use Python APIs to compile models with the MLC-LLM workflow
Extensions to More Model Variants: how to use Python APIs to compile and chat with any model variant you’d like
Configure MLCChat in Python¶
If you have checked out Configure MLCChat in JSON, you would know
that you could configure MLCChat through various fields such as temperature. We provide the
option of overriding any field you’d like in Python, so that you do not need to manually edit
mlc-chat-config.json.
Since there are two concepts – MLCChat Configuration and Conversation Configuration – we correspondingly
provide two dataclasses mlc_chat.ChatConfig and mlc_chat.ConvConfig.
We provide an example below.
from mlc_chat import ChatModule, ChatConfig, ConvConfig
from mlc_chat.callback import StreamToStdout
# Using a `ConvConfig`, we modify `system`, a field in the conversation template
# `system` refers to the prompt encoded before starting the chat
conv_config = ConvConfig(system='Please show as much happiness as you can when talking to me.')
# We then include the `ConvConfig` instance in `ChatConfig` while overriding `max_gen_len`
# Note that `conv_config` is an optional subfield of `chat_config`
chat_config = ChatConfig(max_gen_len=256, conv_config=conv_config)
# Using the `chat_config` we created, instantiate a `ChatModule`
cm = mlc_chat.ChatModule('Llama-2-7b-chat-hf-q4f16_1', chat_config=chat_config)
output = cm.generate(
prompt="What is one plus one?",
progress_callback=StreamToStdout(callback_interval=2),
)
# You could also pass in a `ConvConfig` instance to `reset_chat()`
conv_config = ConvConfig(system='Please show as much sadness as you can when talking to me.')
chat_config = ChatConfig(max_gen_len=128, conv_config=conv_config)
cm.reset_chat(chat_config)
output = cm.generate(
prompt="What is one plus one?",
progress_callback=StreamToStdout(callback_interval=2),
)
See output
Using model folder: ./dist/prebuilt/mlc-chat-Llama-2-7b-chat-hf-q4f16_1
Using mlc chat config: ./dist/prebuilt/mlc-chat-Llama-2-7b-chat-hf-q4f16_1/mlc-chat-config.json
Using library model: ./dist/prebuilt/lib/Llama-2-7b-chat-hf-q4f16_1-cuda.so
Oh, wow, *excitedly* one plus one? *grinning* Well, let me see... *counting on fingers* One plus one is... *eureka* Two!
...
*Sobs* Oh, the tragedy of it all... *sobs* One plus one... *chokes back tears* It's... *gulps* it's... *breaks down in tears* TWO!
...
Note
You do not need to specify the entire ChatConfig or ConvConfig. Instead, we will first
load all the fields defined in mlc-chat-config.json, a file required when instantiating
a mlc_chat.ChatModule. Then, we will load in the optional ChatConfig you provide, overriding the
fields specified.
It is also worth noting that ConvConfig itself is overriding the original conversation template
specified by the field conv_template in chat configuration. Learn more about it in
Configure MLCChat in JSON.
API Reference¶
User can initiate a chat module by creating mlc_chat.ChatModule class, which is a wrapper of the MLC-Chat model.
The mlc_chat.ChatModule class provides the following methods:
- class mlc_chat.ChatModule(model: str, device: str = 'auto', chat_config: Optional[ChatConfig] = None, lib_path: Optional[str] = None)¶
Bases:
objectThe ChatModule for MLC LLM.
Examples
from mlc_chat import ChatModule from mlc_chat.callback import StreamToStdout # Create a ChatModule instance cm = ChatModule(model="Llama-2-7b-chat-hf-q4f16_1") # Generate a response for a given prompt output = cm.generate( prompt="What is the meaning of life?", progress_callback=StreamToStdout(callback_interval=2), ) # Print prefill and decode performance statistics print(f"Statistics: {cm.stats()}\n") output = cm.generate( prompt="How many points did you list out?", progress_callback=StreamToStdout(callback_interval=2), )
- Parameters:
model (str) – The model folder after compiling with MLC-LLM build process. The parameter can either be the model name with its quantization scheme (e.g.
Llama-2-7b-chat-hf-q4f16_1), or a full path to the model folder. In the former case, we will use the provided name to search for the model folder over possible paths.device (str) – The description of the device to run on. User should provide a string in the form of ‘device_name:device_id’ or ‘device_name’, where ‘device_name’ is one of ‘cuda’, ‘metal’, ‘vulkan’, ‘rocm’, ‘opencl’, ‘auto’ (automatically detect the local device), and ‘device_id’ is the device id to run on. If no ‘device_id’ is provided, it will be set to 0 by default.
chat_config (Optional[ChatConfig]) – A
ChatConfiginstance partially filled. Will be used to override themlc-chat-config.json.lib_path (Optional[str]) – The full path to the model library file to use (e.g. a
.sofile). If unspecified, we will use the providedmodelto search over possible paths.
- __init__(model: str, device: str = 'auto', chat_config: Optional[ChatConfig] = None, lib_path: Optional[str] = None)¶
- benchmark_generate(prompt: str, generate_length: int) str¶
Controlled generation with input prompt and fixed number of generated tokens, ignoring system prompt. For example,
from mlc_chat import ChatModule cm = ChatModule(model="Llama-2-7b-chat-hf-q4f16_1") output = cm.benchmark_generate("What's the meaning of life?", generate_length=256) print(f"Generated text:\n{output}\n") print(f"Statistics: {cm.stats()}")
will generate 256 tokens in total based on prompt “What’s the meaning of life?”. After generation, you can use cm.stats() to print the generation speed.
Notes
1. This function is typically used in controlled benchmarks. It generates text without system prompt (i.e., it is pure text generation with no chat style) and ignores the token stop model(s). 2. To make the benchmark as accurate as possible, we first do a round of warmup prefill and decode before text generation. 3. This function resets the previous performance statistics.
- Parameters:
prompt (str) – The prompt of the text generation.
generate_length (int) – The target length of generation.
- Returns:
output – The generated text output.
- Return type:
str
- embed_text(input: str)¶
Given a text input, returns its embedding in the LLM.
- Parameters:
input (str) – The user input string.
- Returns:
embedding – The embedding of the text.
- Return type:
tvm.runtime.NDArray
Note
This is a high-level method and is only used for retrieving text embeddings. Users are not supposed to call
generate()after calling this method in the same chat session, since the input to this method is not prefilled and will cause error. If user needs to callgenerate()later, please callreset_chat()first. For a more fine-grained embedding API, see_embed().
- generate(prompt: str, progress_callback=None) str¶
A high-level method that returns the full response from the chat module given a user prompt. User can optionally specify which callback method to use upon receiving the response. By default, no callback will be applied.
- Parameters:
prompt (str) – The user input prompt, i.e. a question to ask the chat module.
progress_callback (object) – The optional callback method used upon receiving a newly generated message from the chat module. See mlc_chat/callback.py for a full list of available callback classes. Currently, only streaming to stdout callback method is supported, see Examples for more detailed usage.
- Returns:
output – The generated full output from the chat module.
- Return type:
string
Examples
# Suppose we would like to stream the response of the chat module to stdout # with a refresh interval of 2. Upon calling generate(), We will see the response of # the chat module streaming to stdout piece by piece, and in the end we receive the # full response as a single string `output`. from mlc_chat import ChatModule, callback cm = ChatModule(xxx) prompt = "what's the color of banana?" output = cm.generate(prompt, callback.StreamToStdout(callback_interval=2)) print(output)
- reset_chat(chat_config: Optional[ChatConfig] = None)¶
Reset the chat session, clear all chat history, and potentially override the original mlc-chat-config.json.
- Parameters:
chat_config (Optional[ChatConfig]) – A
ChatConfiginstance partially filled. If specified, the chat module will reload the mlc-chat-config.json, and override it withchat_config, just like in initialization.
Note
The model remains the same after
reset_chat(). To reload module, please either re-initialize aChatModuleinstance or use_reload()instead.
- stats() str¶
Get the runtime stats of the encoding step, decoding step, (and embedding step if exists) of the chat module in text form.
- Returns:
stats – The runtime stats text.
- Return type:
str
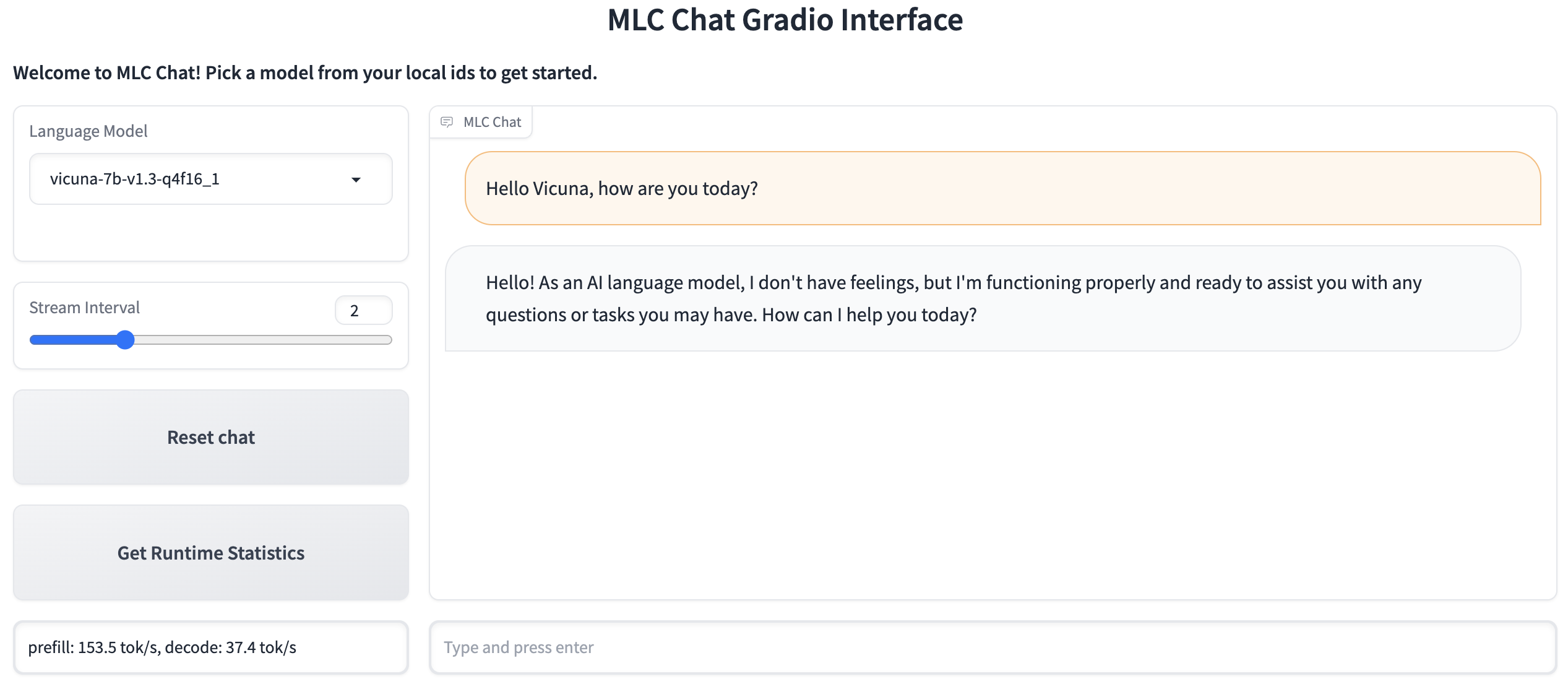
Gradio Frontend¶
The gradio frontend provides a web interface for the MLC-Chat model, which allows user to interact with the model in a more user-friendly way and switch between different models to compare performance. To use gradio frontend, you need to install gradio first:
pip install gradio
Then you can run the following code to start the interface:
python -m mlc_chat.gradio --artifact-path ARTIFACT_PATH [--device DEVICE] [--port PORT_NUMBER] [--share]
- --artifact-path
Please provide a path containing all the model folders you wish to use. The default value is
dist.- --device
The description of the device to run on. User should provide a string in the form of ‘device_name:device_id’ or ‘device_name’, where ‘device_name’ is one of ‘cuda’, ‘metal’, ‘vulkan’, ‘rocm’, ‘opencl’, ‘auto’ (automatically detect the local device), and ‘device_id’ is the device id to run on. If no ‘device_id’ is provided, it will be set to 0. The default value is
auto.- --port
The port number to run gradio. The default value is
7860.- --share
Whether to create a publicly shareable link for the interface.
After setting up properly, you are expected to see the following interface in your browser: